
I do code a lot with AI.
I can easily say that I use GPT4 99% of the time for coding.
Usually, I code PHP, JS, HTML, or CSS. Sometimes Python or WebGL Shader.
Coding with LLMs needs a bit of different thinking and prompting.
Whatever the model we have a limited window of context length.
AI companies love to oversell their numbers like “You can give a book to our model and it will stay coherent” hell no. Benchmarks don’t support those claims. This is the biggest challenge with LLMs we can’t work with a very long context yet.
Another challenge is hallucinations. LLM models love to dream about the things you don’t ask. It only takes one word to make them hallucinate. ONE wrong WORD.
For now, we have to deal with these problems.
I do test and use some Open Source models but that will be another article for later. We have better control on Open Source models compared to GPT4.
I will focus on ChatGPT examples only in this article because I use GPT4 mostly.
Saving Tokens!
Write your prompts clearly and simply.
After your first prompt rate the result/answer. See if the result/answer is logical and good for you. If not edit the first prompt and regenerate again.

In time we will get better at prompting the AI. But most of the time one shot prompting won’t work. When the result/solution/answer is bad just edit the first prompt and re-generate the answer. This will save the context window for the multiple-shot long problem-solving or coding.
Keep fine-tuning the first prompt until you get a good result. With this method, we will keep our first prompt one-shot again and again. When you get a good answer start your conversation from that point on.
This type of prompt editing and perfecting the first prompt is key to saving tokens.
It is not just for the first prompt you can use this method anytime. You can do this in the second or third prompt and regenerate all tree again.
OpenAI says GPT4 context size is big 32k (update: it is 128k now) but not really when you need to write long prompts or need long answers that window closes faster than you think.
Especially when coding. Context window closes very fast I don’t know why it is like coding tokens 10 times more expensive than normal tokens. Still investigating not sure yet.1
With this method, I save so much context window and I always have space to ask for more coherent longer results later in the conversations.
Nudging the AI to the Right Path
When you are giving your prompt to AI you need to give better context.
Let’s write a JavaScript code with AI as an example. This will give a better idea of what I am talking about.
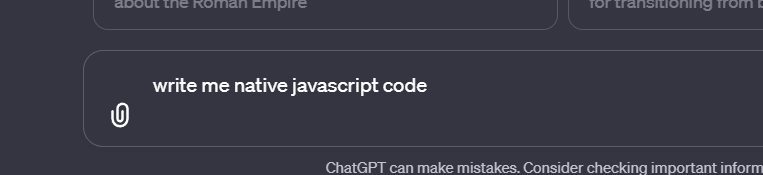
I said native javascript because there are millions of javascript libs and frameworks out there AI can think about react or vue or whatever so I am just eliminating that possibility.
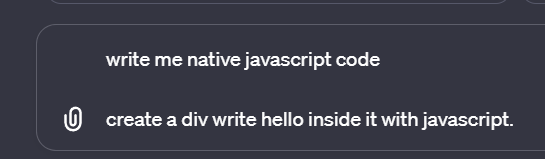
I wrote with javascript because if I didn’t say that 50% of the time AI will write html code. Giving with javascript word eliminates that possibility.

Here 2 things are important. Double quotes “ and . dots.
Yes, dots.
Always give the coding prompt in precise sections. Just like coding it needs to be clear like function blocks or variables or arrays.
Here is the result one-shot. Promise 🖐 one-shot result.
See the Pen Untitled by sinanisler (@sinanisler) on CodePen.
Let’s make the example a bit harder. I am pretty sure this will create a bug. Let’s see how it will implement the color. Notice that I told “give the color to dom” but I am not sure if it will give to div as background or text as color let’s see.
Here is the result;
See the Pen Untitled by sinanisler (@sinanisler) on CodePen.
It has picked the text color but created the bug too. When a random hello clicked it gives the color to text but never removes it.
Let’s edit the prompt one last time and perfect the code.
Here is the result. It only took us editing the prompt a couple of times and we are still in the first shot and have our all context window to us.
See the Pen Untitled by sinanisler (@sinanisler) on CodePen.
After this point, the GPT4 hallucination possibility is very low too. Once you lock the first prompt and the result, the rest will be easy as long as you keep your context window.
Now the AI Model knows what the question is and what is the result we like. Now it will always consider these points while giving other answers.
I wanted to make this example a bit simple but usually I give more specific alignment words too.
For example, when I code PHP for WordPress I directly give hints the core function names to align the model to start writing the right code. This method is OP if you can do it just do it.
I have some Custom GPT models for coding too but they have just system prompts for alignments and they are too specific to write here as examples.
This is how I code simply.
- I think this is related to the multi-modality. I am guessing coder model of GPT4 has less context size than other models ↩︎
Thanks for sharing!
What about other LLM? like Claude or even the new o1? do you used them for coding as well?
Of course
Every time someone makes a major model update or release something new, I go and test it.
The biggest issue is that creating a great model that surpasses counterparts on benchmarks is not enough. These models have hidden system prompts, and the smarter your system prompts are, the smarter your output becomes.
Sometimes, a big foundation model is released with only raw benchmarks, without fine-tuning the system prompts and output for the end user. That creates disappointment for me every time. This happens across all major models. OpenAI has almost perfected the process of releasing new models, but others are still a bit behind in this regard.
I’ve been using ChatGPT Plus since it launched (23 months+) and still pay for it. I use ChatGPT almost exclusively for coding, and to this day, I always come back to OpenAI models.
Lately, I’ve been using ChatGPT with DeepSeek R1 a lot, but ChatGPT is still my main go-to LLM. o3-mini-high and o1 are great they are by far the best coders.